HuTieuBERT
When Morphology Hides in Plain Sight: Breaking the Isolation in Vietnamese and Beyond
1Faculty of Computer Science and Engineering, Ho Chi Minh City University of Technology (HCMUT), VNU-HCM, Ho Chi Minh City, Vietnam
3Mohamed bin Zayed University of Artificial Intelligence, Abu Dhabi, UAE
Accepted to ACL 2026 Main Conference, poster presentation.
Abstract
In isolating languages such as Vietnamese, core morphological structure is encoded not by inflection but by the composition and ordering of monosyllabic morphemes, yet standard Transformer encoders largely overlook this signal. We introduce HuTieuBERT, a morpheme-aware Transformer that augments a pretrained Vietnamese encoder with two lightweight inductive biases: (i) Adaptive Boundary-Token Fusion, which integrates BMES-based morpheme boundary embeddings into token representations via a learnable gate, and (ii) a Morpheme-Aware Attention Bias, which injects a fixed structural attention matrix into early self-attention layers while minimally perturbing the pretrained attention geometry. Across a suite of Vietnamese POS, NER, and sentence-level classification benchmarks, HuTieuBERT consistently outperforms strong baselines, with the largest gains on syntactic tasks. Hyperparameter ablations show a broad regime in which structural biases improve accuracy without destabilizing representations. Applying the same design to ChineseBERT (Chinese-BERT-wwm) yields MAChineseBERT, which improves F1 and produces more balanced tag distributions on Chinese POS and NER, suggesting that explicit morpheme-aware attention is a portable and effective strategy for modeling isolating languages.
This repository implements a morpheme-aware Transformer architecture that enhances pretrained encoders with explicit morphological structure for isolating languages.
By introducing two lightweight inductive biases:
- Adaptive Boundary-Token Fusion
- Morpheme-Aware Attention Bias
The model effectively captures compound cohesion and morpheme boundaries that standard Transformers often overlook, while remaining optimized for Vietnamese.
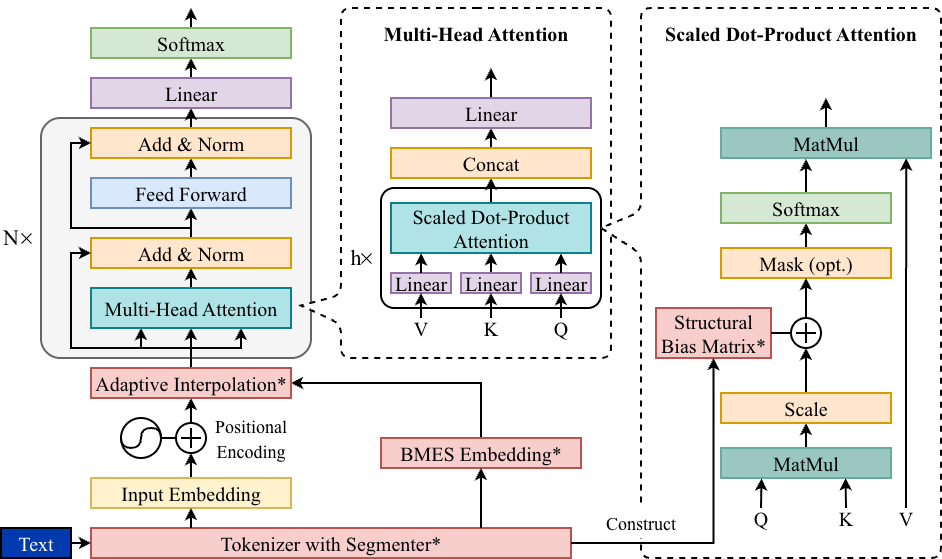
figures/ReDrawHuTieuBERT.pngThe design is portable to other isolating languages like Mandarin Chinese, consistently improving performance on syntactic tasks such as POS tagging and Named Entity Recognition (NER).
Adaptive Boundary-Token Fusion
Subword Alignment
- Syncing Labels: This step aligns word-structure tags (BMES) with the smaller sub-units of text created during tokenization:
- B (Begin): Marks the first syllable or character of a multi-syllable word.
- M (Middle): Applied to the internal syllables or characters of a multi-syllable word.
- E (End): Marks the final syllable or character of a multi-syllable word.
- S (Single): Used for standalone words that consist of only one syllable or character.
- Maintaining Structure: By expanding these tags, the model ensures that multi-syllable words keep their linguistic meaning even when broken into pieces.

figures/alignment.pngAdaptive Interpolation Layer
- Blending Information: This module combines standard word data with specific "boundary" information that marks where words start and end.
- Smart Filtering: A "gate" automatically decides how much boundary information is needed for each word based on its context.
- Rich Representation: The result is a more complete digital representation of the text that respects the natural boundaries of the language.
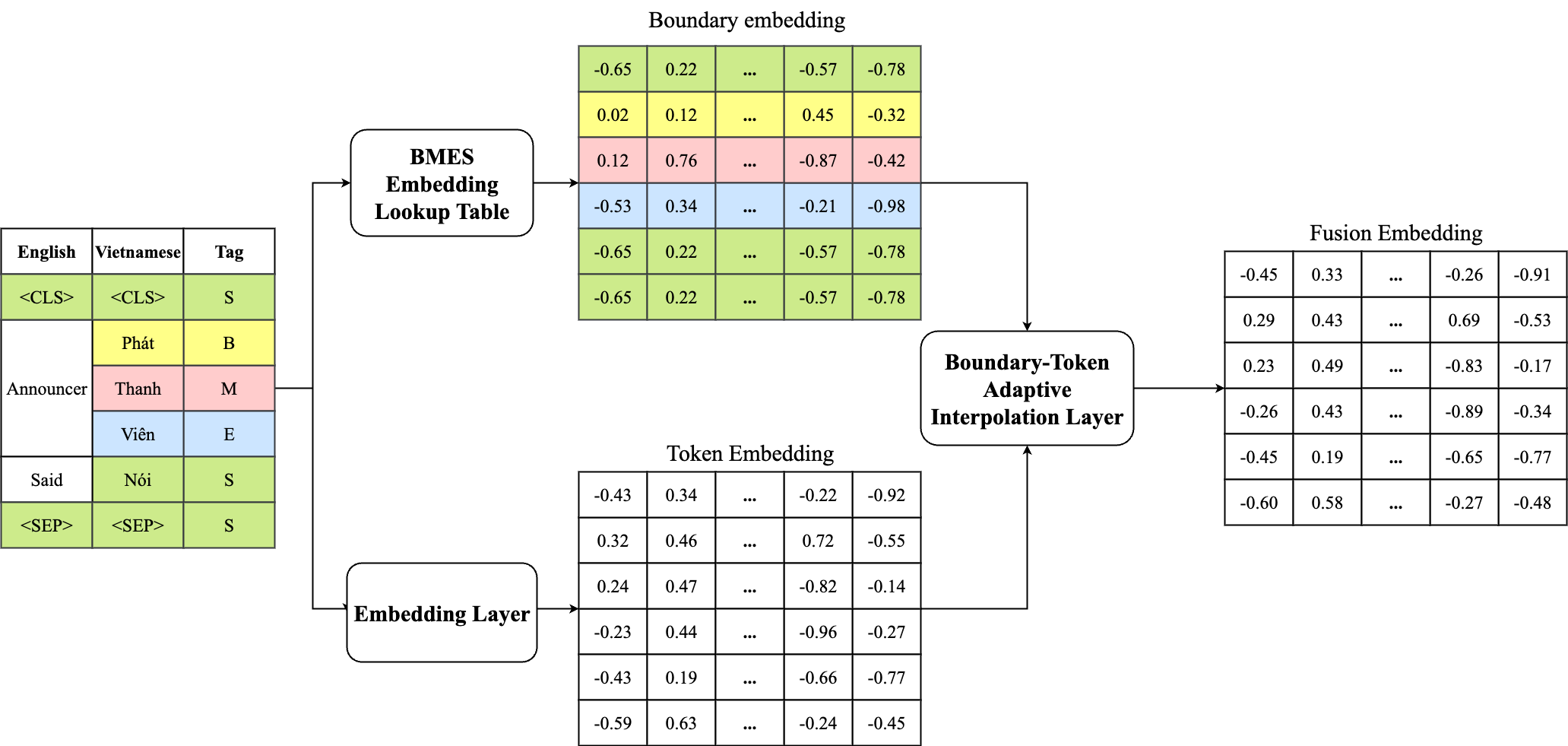
figures/embeddings.pngMorpheme-Aware Attention Bias
This module guides the model's focus by injecting a fixed structural prior into the early self-attention layers. It ensures that the "attention" mass respects the natural boundaries of compounds rather than spreading too thin across unrelated words.
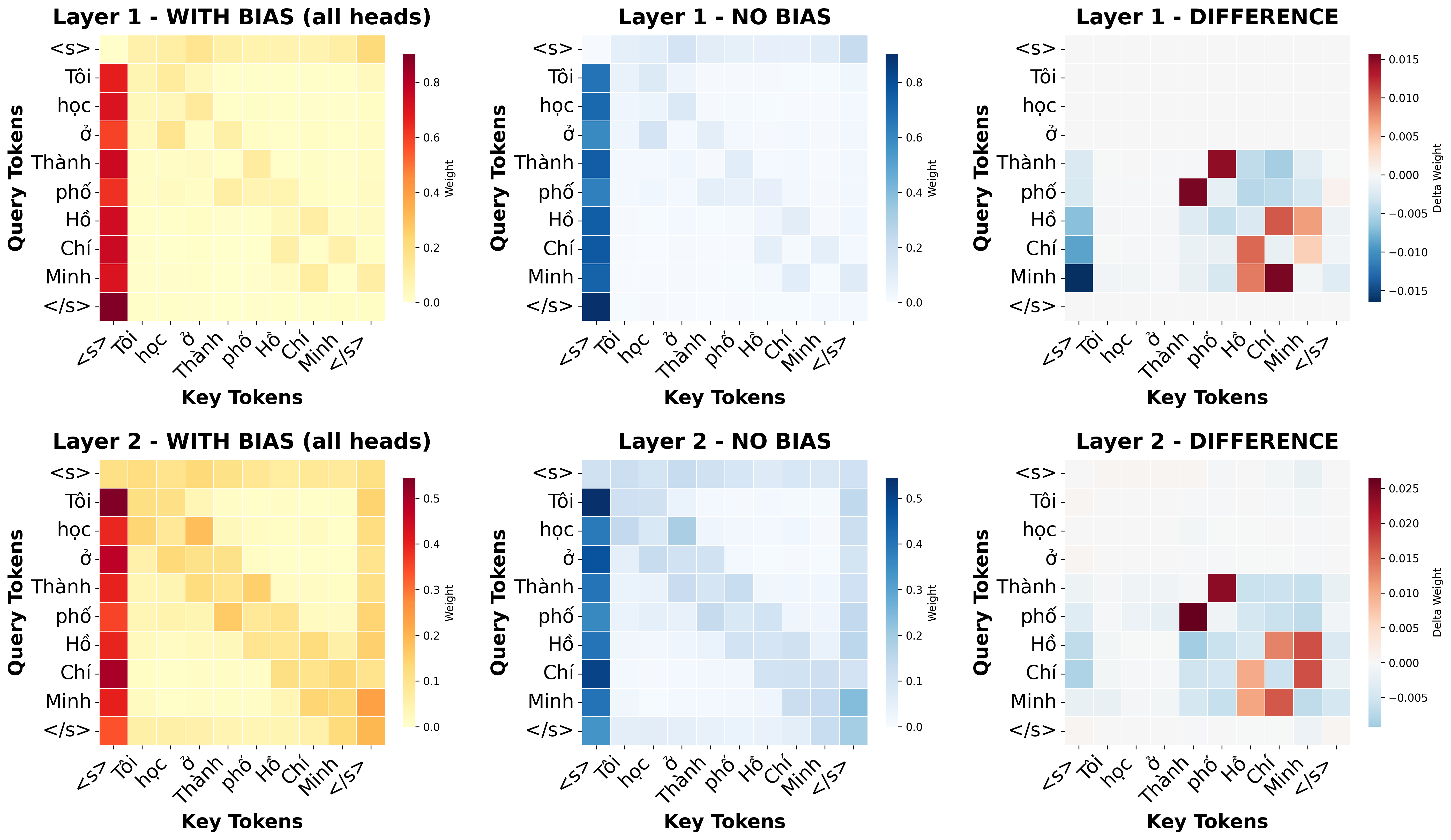
figures/multi_layer_attention_1-2_all.pngThe bias is controlled by a matrix using four key parameters to modulate relationship scores:
- Alpha (
α): Strengthens focus between tokens that belong to the same compound phrase. - Beta (
β): Penalizes or "mutes" attention between tokens that belong to different compounds. - Gamma (
γ): Highlights and adjusts the importance of single-word units. - Delta (
δ): Controls the strength of a token's focus on itself (self-attention bias).
By reweighting these connections, the model maintains a stable internal geometry while gaining a clearer understanding of linguistic structure. This method not only work with Vietnamese but also other Isolating Languages like Mandarin Chinese, Thai...
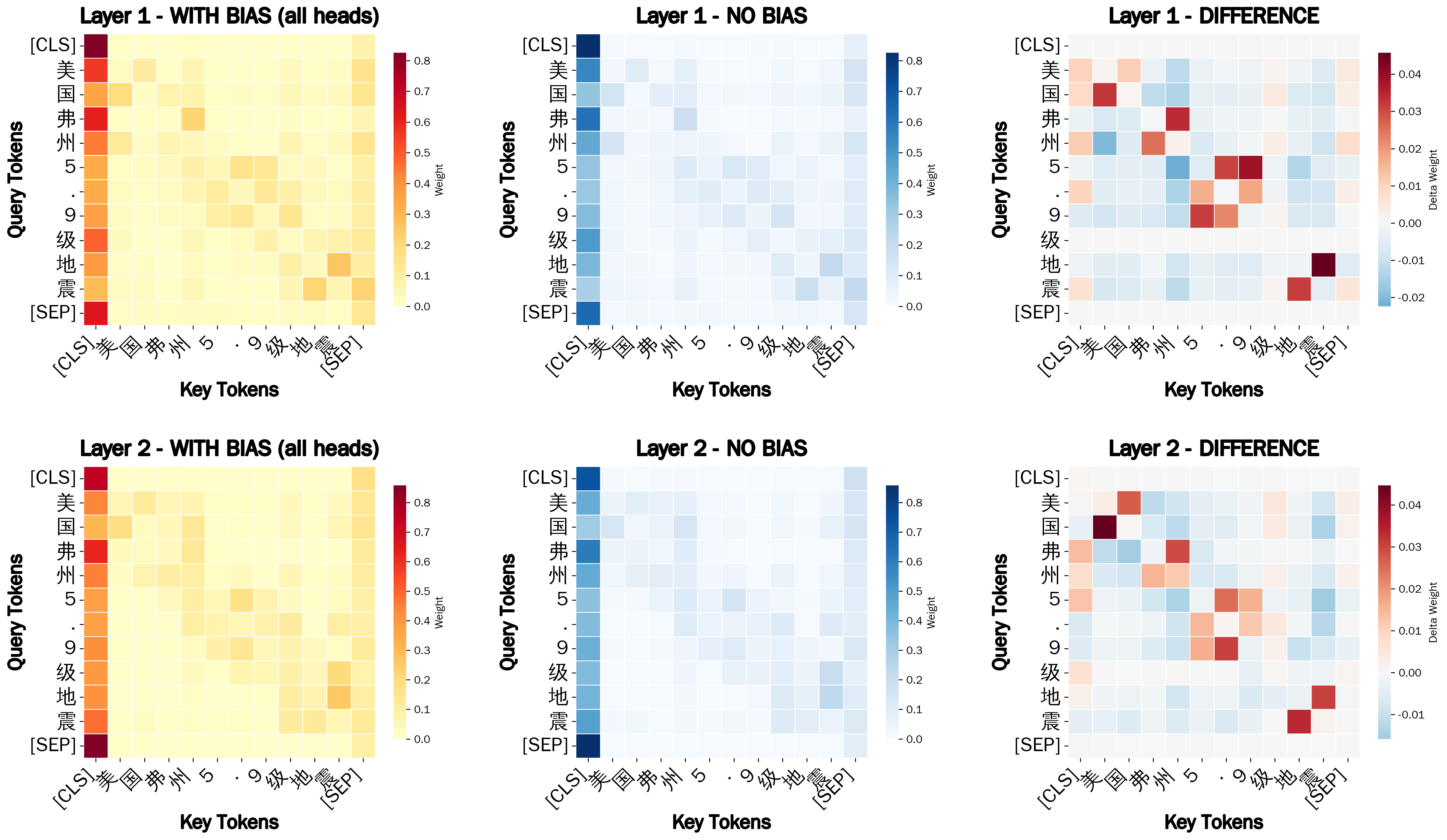
figures/machinesebert_attention_1-2_all.pngAcknowledgement
If you find this work helpful, please consider citing our paper:
Full citation details will be updated after the camera-ready version is available.